TDD
테스트 주도 개발(Test Driven Development) 또는 테스트 우선 개발(Test First Development)이란, 특정 기능을 테스트하기 위한 테스트 코드를 먼저 작성한 후에 그 테스트를 통과시키기 위해 실제 기능을 개발하는 개발 방법을 말한다. TDD에서는 이렇게 테스트 코드를 만들고 테스트를 통과시키는 짧은 주기의 사이클을 계속해서 반복하며 프로그램을 완성시켜 나간다. 이 주기는 세가지 단계로 나누어진다.

RED : 실패하는 테스트 코드를 작성한다.
GREEN : 테스트가 성공하도록 실제 기능을 구현한다.
BLUE : 구현한 코드를 리팩토링한다.
(1) 테스트 코드 작성
제일 첫번째 단계에서는 실패하는 테스트 코드를 작성한다. 현재 구현하고자 하는 기능에 대한 단위 테스트(Unit Test)를 작성하는 것이다. 아직 기능을 구현하지 않았으니 당연히 실패한다.
- 어떤 입력이 들어올 예정인지
- 그 때 어떤 함수가 호출되는지
- 그러면 어떤 결과가 나와야 하는지
(2) 기능 구현
테스트코드가 작성되었으면 다음은 그 코드가 통과되도록 기능을 구현한다.
- 호출된 함수의 내부 작성
(3) 리팩토링
테스트가 통과되었으면 마지막으로, 구현한 코드를 깔끔하게 정리한다. 중복된 코드를 함수로 추출하거나, 더 좋은 형태로 수정한다. 이 과정을 리팩토링이라고 한다. 리팩토링이 완료되면 테스트를 한번 더 수행하여 여전히 통과되는지 확인한다.
왜 하는가
코드에 대한 확신을 가질 수 있다.
이런 식으로 테스트를 먼저 작성해두면, 나중에 기능의 변경이나 추가가 있을 때 새로 작성한 코드가 기존의 기능을 건드리지 않고 안정적으로 동작하는지 테스트 한번에 확인할 수 있다. 또한 매번 테스트가 성공하는 것을 보면서 작성한 코드에 대한 확신을 가질 수 있어 가벼운 마음으로 다음 단계로 넘어갈 수 있다.
빠짐 없이 테스트 할 수 있다.
TDD의 기본 원칙은 "실패한 테스트를 성공시키기 위한 목적이 아닌 코드는 만들지 않는다"는 것이다. 따라서, 이 원칙을 잘 따랐다면 만들어진 모든 코드는 빠짐없이 테스트로 검증된 것이라고 볼 수 있다. 개발을 먼저 하고 미루고 미루다 테스트 코드를 작성한다면 성의 없는 테스트를 하거나 몇몇 기능은 테스트를 아예 빼먹을 수도 있다. TDD 방식으로 개발한다면 테스트를 빼먹지 않고 꼼꼼하게 만들 수 있다!
전체적인 개발 속도가 빨라진다.
누군가는 매번 테스트코드를 작성하면 전체적인 개발 일정이 지연되지 않을까 생각할지도 모르겠다. 하지만 테스트 코드를 작성하는것은 실제 기능을 구현하는것보다 상대적으로 간단하기때문에 생각보다 시간이 오래 걸리지 않는다. 오히려 테스트 덕분에 오류를 빨리 잡아낼 수 있기 때문에 전체적인 개발 속도는 빨라진다. 반대로 테스트가 없다면, 개발자는 프로그램을 일일히 실행시켜 보면서 어느 부분에서 오류가 발생하는지 확인해봐야 할 것이다.
기능설계와 테스트
테스트 코드를 작성하는것은 결국 '어떤 기능이 필요한지'를 정의하는것과 비슷하다. 즉, 추가하고 싶은 기능을 테스트 코드로 표현하는 것이다. 이렇게 작성된 테스트들은 잘 작성된 기능정의서처럼 볼 수 있다. 테스트코드를 작성하는것으로 기능설계와 테스트라는 두가지 작업을 동시에 끝내는 것이다.
어떻게 하는가 - 테스트 코드는 어떻게 작성하는가
그러면 테스트 코드는 어떤식으로 작성해야 할까? 예를 들어, DB에 접속하여 신규 사용자 데이터를 추가하는 MyDBConnection class에 대한 테스트를 작성한다고 생각 해 보자.

기능적으로 어떤 회원 정보를 입력하면 DB에 해당 데이터가 저장되고, 똑같은 정보로 DB를 조회했을 때 동일한 회원 정보가 조회되어야 한다. 이를 코드로 표현하면 다음과 같다.
public class UnitTest {
public static void main(String[] args) throws SQLException {
//테스트할 DB 인터페이스 객체라고 가정
MyDBConnection db = new MyDBConnection();
User user = new User();
user.setEmail("hong@example.com");
user.setName("홍길동");
user.setAge(20);
db.add(user);
System.out.println(user.getEmail() + "등록 성공");
User user2 = db.get(user.getEmail());
System.out.println(user2.getName());
System.out.println(user2.getAge());
System.out.println(user2.getEmail() + "조회 성공");
}
}
그런데, 이 테스트 코드엔 몇가지 문제가 있다.
(1) 먼저, 조회한 데이터가 입력한 데이터와 같은지 확인해주지 않고 화면에 출력하여 개발자가 눈으로 직접 확인해야 한다.
(2) 그리고 결과가 성공이든 아니든 "조회 성공"이라는 텍스트가 출력된다.
(3) 마지막으로, 테스트가 main 함수에 작성되었기 때문에 매번 서로 다른 테스트 클래스를 동작시켜야 한다.
모든 기능에 대하여 테스트를 작성하면서 결과를 개발자가 일일히 눈으로 확인하는것은 매우 비효율적인 일이다. 따라서 테스트 코드가 테스트의 성공/실패 여부를 자동으로 판단하도록 자동화시켜야 한다. 이를 고쳐 보자.
우선, user와 user2의 데이터가 같은지 판단하고, 모든 데이터가 같을 때에만 테스트 성공 메세지가 출력되도록 다음과 같이 수정할 수 있다.
User user2 = db.get(user.getEmail());
if(!user.getName().equals(user2.getName())){
System.out.println("테스트 실패(name)");
}
else if(user.getAge() != user2.getAge()){
System.out.println("테스트 실패(age)");
}
else {
System.out.println("조회 테스트 성공");
}
두번째로, 테스트코드를 모아 놓은 클래스를 만들어서 여러개의 테스트가 모두 실행되도록 수정하면 다음과 같다.
public class UnitTests {
//테스트할 DB 인터페이스 객체라고 가정
MyDBConnection db = new MyDBConnection();
public static void main(String[] args) throws SQLException {
AddUserTest();
AnotherTest();
//...
}
public void AddUserTest(){
User user = new User();
user.setEmail("hong@example.com");
user.setName("홍길동");
user.setAge(20);
db.add(user);
System.out.println(user.getEmail() + "등록 성공");
User user2 = db.get(user.getEmail());
if(!user.getName().equals(user2.getName())){
System.out.println("테스트 실패(name)");
}
else if(user.getAge() != user2.getAge()){
System.out.println("테스트 실패(age)");
}
else {
System.out.println("조회 테스트 성공");
}
}
public void AnotherTest(){
//...
}
}
이런 식으로 여러개의 테스트를 스스로 수행 가능하고, 기대하는 결과에 대한 확인까지 해주는 자동화된 테스트를 만들어 두는 것이다. 이 다음은 이 테스트를 통과하도록 MyDBConnection 클래스의 add, get 함수를 구현하고, 테스트가 통과되는것을 확인하면 되겠다.
JUnit
위와 같은 테스트 코드의 작성을 보다 편하게 도와주는 프레임워크가 있다. 바로 JUnit이다.
JUnit은 프레임워크다.
프레임워크의 기본 동작 원리는 제어의 역전IoC 이다. 프레임워크는 개발자가 만든 클래스에 대한 제어 권한을 넘겨받아서 주도적으로 애플리케이션의 흐름을 제어한다. 따라서 프레임워크를 사용할 때엔 main() 메소드도 필요 없고 오브젝트를 만들어서 실행시켜 줄 필요도 없다.
위에서 만든 테스트를 JUnit 프레임워크에서 동작시키려면 조건 두가지를 따라야 한다.
- 메소드를 public으로 만든다.
- 메소드에 @Test 애노테이션을 붙여 준다.
위의 테스트 코드를 JUnit 프레임워크를 사용하는 코드로 수정하면 다음과 같이 바뀐다.
import org.junit.Test;
public class UnitTests {
//테스트할 DB 인터페이스 객체라고 가정
MyDBConnection db = new MyDBConnection();
@Test
public void AddUserTest(){
User user = new User();
user.setEmail("hong@example.com");
user.setName("홍길동");
user.setAge(20);
db.add(user);
System.out.println(user.getEmail() + "등록 성공");
assertThat(user2.getName(), is(user.getName());
assertThat(user2.getAge(), is(user.getAge());
}
@Test
public void AnotherTest(){
//...
}
}
JUnit의 요구조건 외에도 기존 코드에서 바뀐 부분이 있다.
assertThat(user2.getName(), is(user.getName());
assertThat(user2.getAge(), is(user.getAge());위 코드는 JUnit에서 지원하는 Matcher 이다. assertThat(A,B)는 A가 B 조건을 만족하는지 확인하여 같으면 통과, 다르면 테스트 실패를 발생시킨다. JUnit은 이 밖에도 다양한 Matcher를 지원한다.
https://junit.org/junit5/docs/current/user-guide/#writing-tests-assertions
JUnit 5 User Guide
Although the JUnit Jupiter programming model and extension model will not support JUnit 4 features such as Rules and Runners natively, it is not expected that source code maintainers will need to update all of their existing tests, test extensions, and cus
junit.org
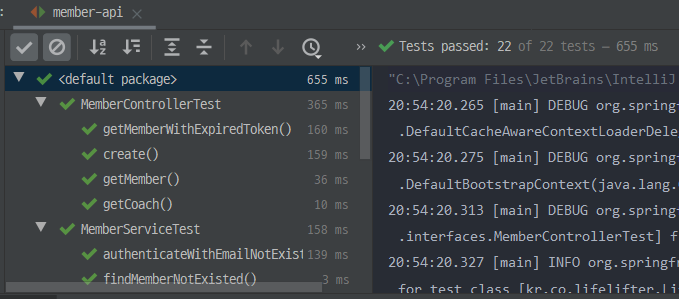
JUnit을 사용하면 테스트를 작성하는것 뿐만 아니라, 실행하고 결과를 확인하는것도 훨씬 간편해진다. IDE에서 JUnit 테스트를 실행하면 테스트가 통과되는 경우와 실패한 경우에 아래 그림과 같이 표시된다. 테스트에 실패할 경우, 어떤 테스트 메소드가 실패했으며 왜 실패했는지가 간략히 표시된다.

참고자료
1. https://marsner.com/blog/why-test-driven-development-tdd/
Why Test-Driven Development (TDD) | Marsner Technologies
%
marsner.com
2. 토비의 스프링 3.1 Vol.1
3. https://velog.io/@velopert/TDD%EC%9D%98-%EC%86%8C%EA%B0%9C#%EC%A0%95%EB%A6%AC
TDD의 소개
TDD (Test Driven Development · 테스트 주도 개발) 에 대해서 알아봅시다! TDD 는 테스트가 개발을 이끌어 나가는 형태의 개발론입니다. 가장 쉽게 설명하자면, 선 테스트 코드 작성, 후 구현 인데요, 이��
velog.io
'스터디' 카테고리의 다른 글
| 인터넷 일반 (0) | 2020.07.14 |
|---|---|
| Spring Framework 소개 (0) | 2020.06.25 |